Medallion Architecture on Databricks: A Manager’s Guide to Faster Insights and Lower Risk
What Bronze–Silver–Gold delivers for your business: faster time-to-insight, lower data risk, clearer ownership, and scalable costs—plus how to adopt it on Databricks with minimal disruption.
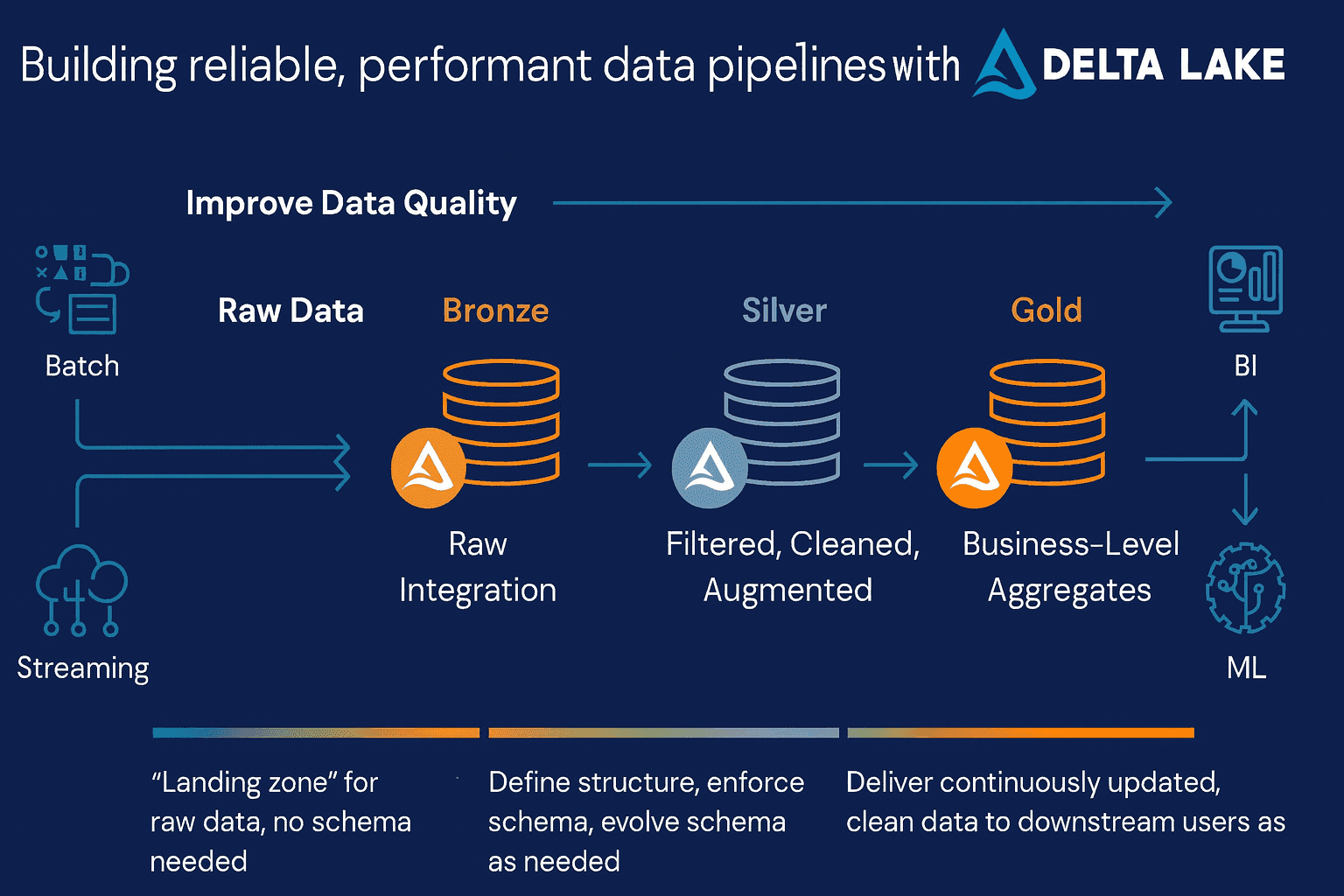
Executive summary: The Medallion architecture (Bronze → Silver → Gold) on Databricks is a proven way to cut data lead times, reduce risk, and scale analytics. It brings order to chaotic data, enforces governance, and shortens the path from raw data to executive reporting and AI.
Why this matters (in business terms)
Leaders need trustworthy, timely data to run revenue, ops, and risk decisions. Traditional stacks slow down because:
- Data arrives fragmented (APIs, files, events) and breaks rigid pipelines.
- Governance is ad-hoc, causing rework and audit headaches.
- Teams duplicate transformations, inflating costs and cycle times.
What the Bronze–Silver–Gold model delivers
Bronze — _Capture everything, safely_
- Business value: No missed signals; audit-ready history.
- Risk reduction: Centralized landing zone (Delta format) with versioning/time travel.
- Outcome: Foundation for traceability and compliance without blocking ingestion.
Silver — _Make data trustworthy and reusable_
- Business value: Fewer “report discrepancies”; faster downstream development.
- Risk reduction: Validations, deduplication, PII policies, standardized semantics.
- Outcome: A governed, reusable data product layer shared across teams.
Gold — _Turn data into decisions_
- Business value: KPI alignment, self-service BI, AI-ready tables.
- Risk reduction: Single source of truth for metrics; reduced spreadsheet logic.
- Outcome: Faster exec dashboards, reliable ML features, and consistent definitions.
Quantifiable benefits you can expect
- Time-to-insight: Cut from weeks to days by decoupling raw ingest from business logic.
- Rework reduction: 30–50% fewer duplicate transformations by standardizing Silver layer.
- Incident reduction: Fewer late-night fixes via ACID transactions and schema enforcement.
- Cost control: Autoscaling compute + right-sized storage; avoid over-provisioned clusters.
- Audit readiness: Lineage, versioning, and data quality checks built into the flow.
Manager takeaway: Medallion turns data engineering into a repeatable operating model—not a string of one-off projects.
How Databricks strengthens the model
- Delta Lake (ACID + versioning): Reliability and traceability at massive scale.
- Workflows & Delta Live Tables (DLT): Declarative pipelines with built-in quality checks.
- Unity Catalog (governance): Centralized access control, lineage, and data masking.
- Elastic compute: Scale up for heavy processing; scale down automatically to save.
Adoption roadmap (low-risk and incremental)
1. 90-minute discovery
Map key data domains, pain points, and target KPIs (e.g., revenue recognition, churn, inventory turns).
2. Pilot (3–6 weeks)
- Scope: 1–2 business KPIs, 2–3 source systems
- Deliver: Bronze/Silver/Gold tables, quality checks, one executive dashboard
- Success: SLA for data freshness (e.g., hourly), trust score (completeness, duplicates)
3. Scale (6–12 weeks)
- Expand to adjacent domains; harden governance (Unity Catalog), alerts, cost policies
- Introduce self-service semantic layer and ML-ready features
4. Operate & optimize (ongoing)
- FinOps guardrails, backlog triage cadence, lineage-based impact analysis
- Quarterly ROI review and roadmap refresh
Investment & operating model
- Team: 1 lead data architect, 1–2 data engineers, 1 analytics engineer (initial).
- Cloud costs: Start small; autoscaling reduces idle spend.
- Operating cadence: Weekly demos, monthly KPI/FinOps review, quarterly governance audit.
Rule of thumb: Aim for one high-value KPI to production every 2–3 weeks once the framework is in place.
Governance and risk management
- Access & privacy: Unity Catalog policies; PII masking at Silver; least privilege by domain.
- Quality: DLT expectations (valid ranges, null checks, referential integrity).
- Lineage & change control: Versioned data + Git-based code; automated impact analysis.
- Compliance: Time travel and audit logs to support internal and external reviews.
Stakeholder alignment (who owns what)
- Business owners (Gold): KPI definitions, acceptance criteria, SLA for freshness.
- Data platform team (Bronze/Silver): Ingestion, quality, governance, lineage.
- Analytics/ML teams (Gold): Models, dashboards, use-case delivery.
- FinOps: Cost policies, usage dashboards, anomaly alerts.
Tip: Treat each Silver/Gold domain as a data product with a named owner and SLA.
Signs you’re ready (or overdue)
- Conflicting numbers across dashboards (sales, margin, churn).
- Frequent pipeline breakages when upstream schemas change.
- Long lead times for “just one more field.”
- Security reviews and audits taking weeks due to unclear lineage.
- BI & AI teams rebuilding the same logic in different tools.
If three or more apply, Medallion will likely pay back in the first two quarters.
Executive FAQ
Will this replace our data warehouse?In many cases, yes—or it becomes the primary store, with a light warehouse footprint during transition.
How fast can we see value?A focused pilot typically delivers a production KPI in 4–6 weeks.
What about vendor lock-in?Delta format is open. Catalog, pipelines, and notebooks are portable with minimal friction.
Do we need a big team to run it?No. A small, senior team can operate the platform; scale the squad as domains grow.
Success metrics to track
- Lead time to new KPI (request → production)
- Data freshness SLA adherence (e.g., hourly updates ≥ 99%)
- Trust score (completeness, duplicates, schema errors)
- Rework rate (duplicate logic across teams)
- Cost per query / per domain (trend and anomalies)
A simple procurement checklist
- ✅ Executive sponsor and 1–2 domain owners
- ✅ Initial KPI list and acceptance thresholds
- ✅ Data access to 2–3 priority sources
- ✅ Budget guardrails (monthly cap and autoscaling policies)
- ✅ Security & compliance requirements (PII, retention, audit)
We can help your company
Want a low-risk pilot plan?We’ll map your current stack, identify the quickest wins, and stand up a Bronze–Silver–Gold pipeline that feeds a real executive KPI—fast.